Understanding the Python Global Interpreter
Have you ever ran a program in Python that does high computation in multiple threads and wondered it’s why slower than running the same code using a single threaded program ?
In this article we’ll talk about what exactly happens under the hood.
What is the GIL?
Let’s start by talking about a concept that you or you may not heard about it , which is the GIL, We’ll see what problems does it solve, how exactly it works, how can the GIL affect the performance of your multi-threaded Python programs and how you can reduce the impact it might have in your multi-threaded programs.
From the Python wiki page: In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe.
In other words CPython does not allow more than one thread to be executed at any given time even you have multiple cores on your machine(It gets even worse as we’ll see later) . The impact of the GIL can’t be seen by developers that don’t write threads in their programs or maybe they do, but only I/O bound threads(reading from sockets, files…). In the other hand, the GIL can be a performance bottleneck when writing CPU-bound threads.
Actually many reasons has led to the decision of bringing the GIL to life, first, Python uses reference counting for memory management. Each object in Python have a reference count variable that keeps track of the number of references that point to the object. When this count reaches zero, the memory occupied by the object is released.
Another reason why the GIL was implemented, is in relation with C extensions. Developers that are writing some C extensions does not have to deal with code being executed from multiple threads at once. The third reason is making the Python interpreter much simpler.
Let’s look at an example of how reference counting works:
>>> import sys
>>>
>>> a = list()
>>> sys.getrefcount(a)
2
In this example the reference count (unexpectedly for some) is 2, we know that one reference comes from the variable a, and the second is the argument passed to sys.getrefcount which will also point to the same list.
The reference counting needs to be protected again multiple threads playing the same object which can lead to a race condition where two threads can increase or decrease a reference count value simultaneously, this can result in a leak memory issue or even worse freeing up an object memory while it’s being used by other threads
In order to prevent these issues from happening, a global lock should be acquired to run the code and released after the execution is done. This ensures that only one thread is executing the code, therefore the GIL effectively restricts bytecode execution to a single core
How can the GIL affect multithreaded programs?
We saw why the GIL was created, but we want to see it in action!
Let’s assume we have a function that does heavy computation
from time import time
def f(n):
while n > 0:
n -= 1
N = 50000000 # 50 million
a = time()
f(N)
print(time() - a)if we try to execute this code, it’ll print the time that the function took to complete its execution, which, in my case, is 2.12 sec
Now, let’s have a threaded version of this
2 threads each one takes half the load(25 Million each), and finger-crossed it’ll run twice faster.
from time import time
from threading import Thread
def f(n):
while n > 0:
n -= 1
N = 50000000
t1 = Thread(target=f, args=[N // 2])
t2 = Thread(target=f, args=[N // 2])
a = time()
t1.start()
t2.start()
t1.join()
t2.join()
print(time() - a)The execution of the threaded version took about 2.55 seconds xD
We expected that each one will run in a CPU core, and since each one is handling half operations of the single threaded version, then it should take half time to complete about which is about 1.06 sec, But as we can see, it was 20% slower which is surprising.
These result were obtained using only 1 CPU core.
Using 2 CPU cores, things starts getting more fun. The sequential code got executed in 2.15s (about same as using a single CPU core), but the threaded version finished in 3.08s which is now 43% slower!
Before going to some explication of why we got this result, we need to know that Python uses real system threads, which means that the threads launched by Python are managed by the operating system. There is no scheduling algorithm implemented in Python.
In the above example we have two CPU bound threads fighting each other to get the gil in order to complete the execution, The Python interpreter allows each thread to execute for a small portion of time(we’ll see how this is exactly done in the next section) then gets paused and allows the other thread to resume its work, this cause a lot of context switching. Before a thread gets paused it has to store its state into a variable and when the other one wants to resume work, it has to restore the state from a variable. This context switching eventually affects performance significantly.
When do threads release/acquire the GIL ?
In a high level, the behavior of the GIL is easy to understand, if a thread is running, it holds on to the GIL, however, if there is any I/O operation (read from a file, socket…) the CPython has been written in a way that the GIL is released to allow other threads to run. But when for example a packet arrive, the interpreter signals the threads to wake up and continue working.
For CPU bound threads, the story is a different.
Actually there is two implementations of the GIL, one was introduced in 1992 and still being used in Python 2.7, the newer version was introduced in 3.2. Let’s explain how each implementation work.
the GIL in Python 2
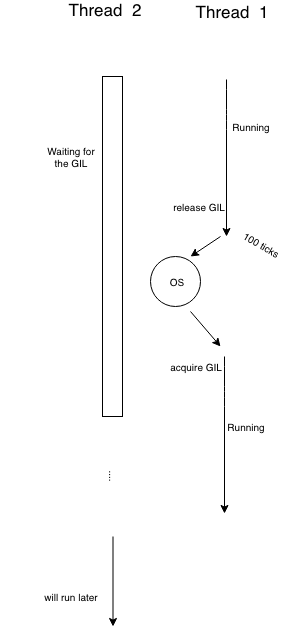
When we’re talking about threads, CPython does a trick to force the threads to release the lock, the interpreter periodically performs a check, where it ensures that a thread does not exceed performing 100 instructions (so called ‘ticks’).
The sys module provides two functions sys.getcheckinterval() that returns the number of check interval and sys.setcheckinterval() that makes it possible to change that interval (it’s 100 by default)
>>> import sys
>>> sys.getcheckinterval()
100In CPython, there is global counter called _Py_Ticker that is totally independent of thread scheduling and has nothing to do with thread, its main goal is to countdown every time the interpreter executes an instruction. When this counter reaches 0, Python does a check, and continue executing. Basically there is two things happening during this check
- Signal handling: Handle any pending signals (for example when you hit control + C), but only on the main thread.
- release and try to reacquire the GIL
We can look into the C implementation where this is defined
static PyThread_type_lock interpreter_lock = 0; /* This is the GIL */
…
int _Py_CheckInterval = 100;
volatile int _Py_Ticker = 0; /* Global counter */
// …
if (--_Py_Ticker < 0) {
// …
_Py_Ticker = _Py_CheckInterval; /* reset counter */
// …
if (interpreter_lock) {
/* Give another thread a chance */
// ..
PyThread_release_lock(interpreter_lock);
/* Other threads may run now */
PyThread_acquire_lock(interpreter_lock, 1);
// …Let’s explain some code, there is actually two parts here, one that does the tick countdown, and the other that handles releasing and reacquiring the lock. The first part was explained above, so we’ll focus on the second part.
Python first checks if the lock is acquired, if so, it releases the lock and reacquires right after, as we can see this is done in two successive function calls. Since the PyThread_release_lock function involves the pthread library, then the OS at that point is free to bring up another thread to run, but this can cause some horrible problem based on the OS scheduler (Linux, Windows..).
Something to clarify about the GIL implementation, is that the locking is based on signals, this means in order to acquire the GIL, the threads need to checks wether the lock is available or not, if not, sleep and wait for a signal, but if the thread has the GIL and wants to release it, the thread throws it and sends a signal.
Basically if you have two CPU bound threads, one of them is running and the second is waiting, when the first one hits the 100 ticks and is “forced” to release the GIL, the PyThread_release_lock function actually fires a signal to the operating system to run another thread, but then it’s up the OS to run whatever process/thread that it thinks should be running at that point. This means the operating system can decide to keep running the first thread even if it exceeds the allowed 100 ticks, and so given the change to run another 100 instructions while the other thread is waiting.
Based on what we just saw, the check interval does not mean thread switching, but rather how frequently the signal is sent to the OS saying you can thread switch if you want to!
Let’s go back to the thread version of our example, context switching and system calls are responsible for slowing down the program, we can actually confirm that by changing the check interval to 1000 ticks, which should lower the number of system calls. We can do that by using the setcheckinterval function from the sys module:
import sys
from time import time
from threading import Thread
sys.setcheckinterval(1000)
def f(n):
…Running this version we got 2.10s which faster by 0.45s(about half a second) than the first threaded version!
Another experiment: Change the check interval to just 10 would result in 5.04s to complete
Why does a multi-threaded program runs slower with multiple cores ?
In a multicore machine, since the threads are managed by the OS, then the OS tries to run as many threads as it can simultaneously on multiple CPUs, hence one thread keeps trying to grab the GIL, while the other one is holding it and running on another CPU, so we end up with a battle between Python and OS, where Python wants to be single threaded even with multiple cores while the OS wants to run multiple threads on different CPU cores, this causes the threaded version to run even slower than having a single core and even more system calls.
the GIL in Python 3
Python 3.2 saw a new GIL implementation since 1992, it’s considered the first major change to the GIL, done by Antoine Pitrou. Let’s explain how this new GIL works.
While the old Global Interpreter Lock counted the execution of the instructions that ran in order to tell the current running thread of give up the GIL, The new lock is based on a hard timeout to force the current thread to release the GIL, when a second thread requests the GIL, the running one is having a default value of 5ms to complete any instructions before the gil is taken away from it. This leads to more predictable switching between threads.
Let’s dive deeper to understand exactly how this is done!
The new GIL is represented by a global variable called gil_drop_request
static volatile int gil_drop_request = 0;A thread will run until this gets set to 1
let’s have a situation where two threads are fighting to run, one of them is holding the GIL and running, the other thread will request the GIL to run, and will wait for 5ms, during this timeout, the suspended thread will either wait for the running one to do I/O, and therefore release the GIL voluntarily, or set the gil_drop_request to 1 after the timeout is finished forcing the thread to release the Lock.
That seems a good approach, but what if the first thread steals the GIL again before being acquired by the other thread just like Python 2.7 ?
Well, that part is covered with some signaling between thread. Basically the thread that just released the GIL will not try to steal it back, but rather wait for a signal (Acknowledgement signal), that will be sent by another thread that just acquired the lock, hence eliminating this GIL battle between threads.
Let’s go back again to our first example and try to run it using Python version 3.6
If we test that same with Python 3.6 we get these results:
- Running sequentially: 2.81s
- Threaded version(2 threads) did the work in just 2.83s
As you just saw, the result are impressive!, But….
Despite the new GIL, there are some edge cases where it does not quite work. We can have an example that shows this issue.
Let’s have an echo server that just returns whatever data was sent to it, this server will be running in a thread, while we’ll have another thread that does some heavy CPU computation of an important problem which is obviously the Fibonacci function!
This is a common pattern that people use in production.
The code of the server part might look like this (2 threads)
import socket
from threading import Thread
def fib(n):
if n < 2:
return 1
return fib(n - 1) + fib(n - 2)
def loop():
i = 50
while i:
i -= 1
print('Fib for %s' % i, fib(i))
def echo_server(port):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('localhost', port))
s.listen(1)
conn, addr = s.accept()
while True:
data = conn.recv(100)
if not data.strip():
break
conn.sendall(data)
print('closed')
conn.close()
t1 = Thread(target=loop)
t2 = Thread(target=echo_server, args=(50000,))
t1.start()
t2.start()
t2.join()
t1.join()For the client, we’ll have it sending a 1000 message and receives them back from the server, and finally does the math of how much time it took to complete
from threading import Thread
from time import time
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('localhost', 50000))
a = time()
try:
for i in range(1000):
s.sendall(b'x' * 100)
data = s.recv(1000)
finally:
s.close()
print(i)
print('done in', time() - a)Running this using Python 3 it finished in about 10.14s.
While using Python 2, it got finished in just 2.21s !!
Since we’re using two I/O operations in the echo server recv and sendall, both these instructions releases the GIL, and gets stolen by the CPU bound thread, and to get it back the I/O thread needs to wait 5ms for recv and another 5ms for sendall. And since we’re sending a 1000 messages hence (5 + 5) x 1000 = 10s
As we can see that the 5ms that is implemented in Python 3 can kill I/O performance, this will manifest itself in a poor response time for example.
IO vs CPU bound battle
In general, OS prefers IO bound threads(higher priority) over CPU bound threads(lower priority), so in a single core machine, if we have two threads, obviously the OS will bring immediately the IO bound thread to run if the CPU bound thread sends a signals that another can run, but on a multicore machine, the behavior is way different. Since the IO bound threads generally spends most of the time waiting for some blocking operations, When a network a packet arrives the OS will wake up the thread to handle that IO operation in an other CPU core, but in other hand the CPU bound thread is already holding the GIL, so the IO thread can’t get the lock and goes back to sleep resulting in hundreds of falls wake ups and system calls, and in some very rare occasions where the IO thread can be lucky enough to grab the GIL before it’s reacquired by the CPU thread.
While writing a threaded program, i think separating I/O and CPU threads can help solve the problem.
The multiprocessing module
The multiprocessing is a very good choices when it comes to separating I/O and CPU threads. Using the echo server as an example, we can think of running the CPU thread as a subprocess, that would not affect the I/O performance at all, because there will be no GIL fight, the only problem with this module, is it introduces way more overhead for creating subprocess, pickling and sending data to those processes. Another reason is the limitation of running a very limited number of process, basically dozens vs thousands when it comes to threads.
Why don't we just remove the GIL?
Well, this is a very hard problem to tackle, in fact there have been several attempts to get rid of the GIL for good like Jython or IronPython or PyPy STM which is based on transactional memory so it eliminates the issue with reference counting with multithreaded programs but one of the problem is that they don’t offer support for C extensions which is probably one of the reason Python is so popular, Also they make the interpreter much more complicated to maintain and develop.
Verdict
Threads are a great option to solve concurrency problem for I/O, and can offer good performance even with the GIL, but get affected when running with CPU bound threads side by side. I think the new GIL solved most of the problems that existed for a long time with Python, but needs more enhancements around some corner cases.
Lastly, if you’re thinking about improving the GIL, you should consider Guido’s sentense:
I'd welcome a set of patches into Py3k only if the performance for a single-threaded program (and for a multi-threaded but I/O-bound program) does not decrease.